数据密集型应用系统设计-数据存储与检索
date
Dec 10, 2021
slug
reading-notes-ddia-storage-and-query
status
Published
tags
读书
系统和网络
summary
type
Page
一个最简单的道理,如果你把东西整理的井井有条,下次就不用查找了。
最简单的数据库
世界上最简单的数据库可以用两个Bash函数实现:
如何使用:
db_set 通过追加数据都文本末尾的方式存储,这种方式十分简单,或者可以说是最简单的记录数据的方式了,每次写入都是追加,每次读取都是从头到尾逐行扫过,在数据量少时十分高效,但很明显当数据量大时扫描会非常慢,这就引出了索引。索引背后的基本想法都是保留一些额外的元数据,这些元数据作为路标,帮助定位想要的数据。
索引是基于原始数据派生而来的额外数据结构,许多数据库允许单独添加与删除索引,而不影响数据的内容,它只影响查询的性能。维护额外的结构会产生开销,特别是在写入时。对于写入,它很难超过简单的追加文件的方式的性能,因为那已经是最简单的操作了。由于每次写数据时,需要更新索引,因此任何类型的索引通常都会降低写的速度。
哈希索引
用 hash map 来构建索引,key 作为 hash map 的 key,value 则是每个键映射到数据文件中的字节偏移量,这样就可以找到每个 value 的位置而不用从头到尾遍历。
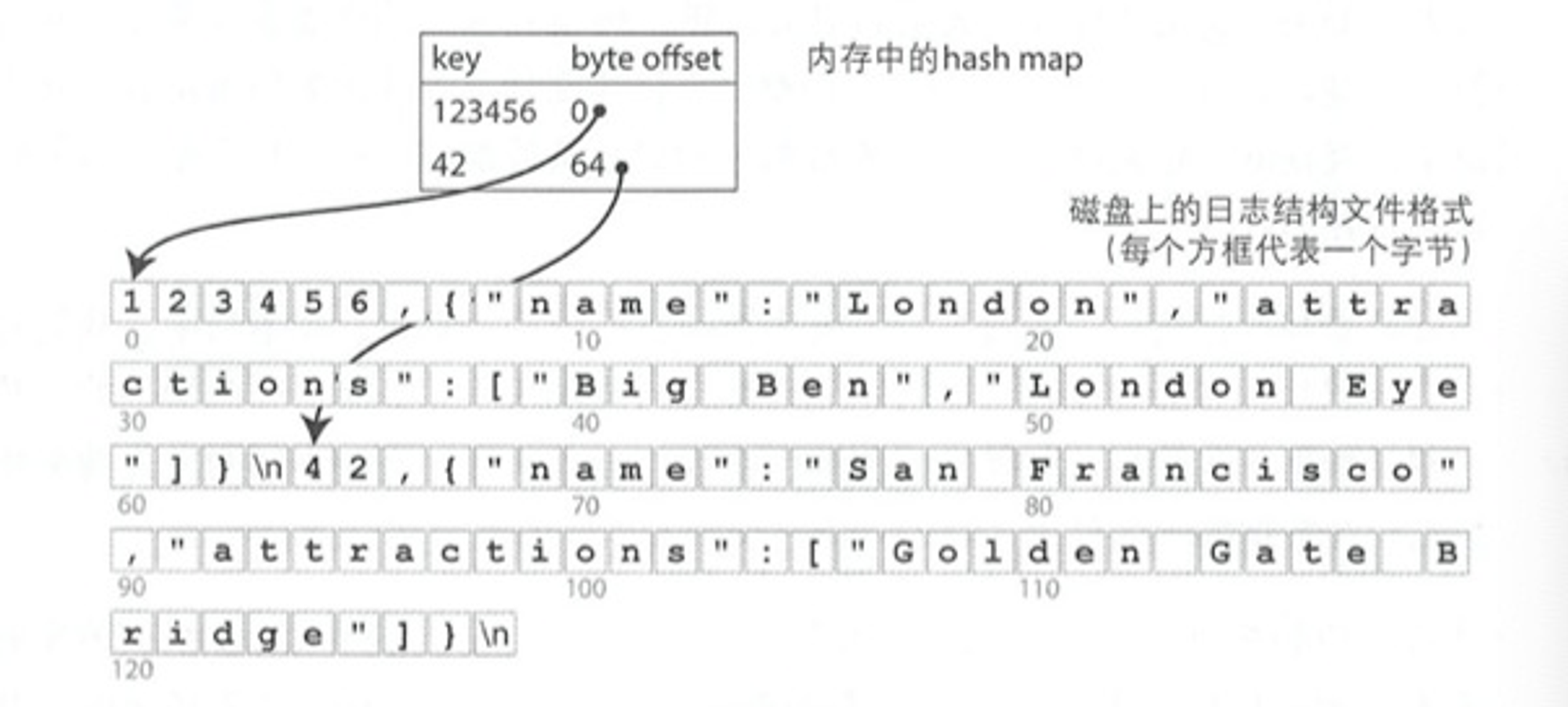
这确实是提高读取速度的一个可行的方法。但还有一个问题,如果一直往一个文件里追加,如何避免将磁盘空间耗尽?解决方案是可以将日志分解成一定大小的段 segment,当文件到达一定大小时就关闭它,并将后续写入到新的段文件中,然后可以在这些段上执行压缩,而压缩意味着丢弃重复的键,并只保留每个键最近的更新,还可以将多个段合并到一起。

另外还有很多细节,简言之有以下这些重要问题:
文件格式:
CSV 不是日志最佳格式,更快更简单的方法是使用二进制格式,首先以字节为单位来记录字符串长度,之后跟上原始字符串。
删除记录:
如果要删除 kv,则必须在数据文件中追加一个特殊的删除记录,当合并日志段时,一单发现删除记录,则会丢弃这个已删除的 k 的所有 v。
崩溃恢复:
如果数据库重启,内存中的 hash map 将丢失,原则上可以重新加载整个段文件重建索引,但这可能需要很长时间,另一种方案是存储hash map 快照,快照可以更快的加载到内存。
部分写入的记录:
数据库随时可能崩溃,包括将记录追加到日志的过程中,这需要检测文件有效性。
并发控制:
由于写入是严格的先后顺序追加到日志中,通常的实现是只有一个写线程,而读取可以同时多个线程读。
追加日志似乎很浪费空间,为什么不原地更新文件?
- 追加和分段合并主要是顺序写,它通常比随机写入快得多,特别是旋转式磁性硬盘。
- 如果段文件是追加的或不可变的,则并发空崩溃恢复要简单很多。
- 合并旧段可以避免随着时间推移数据文件出现碎片化问题。
hash map 也有局限性,最大问题是数据全部都在内存,而内存空间往往比较有效,另外一个问题是 hash map 范围查询效率不高。
SSTables: Sorted String Table 排序字符串表
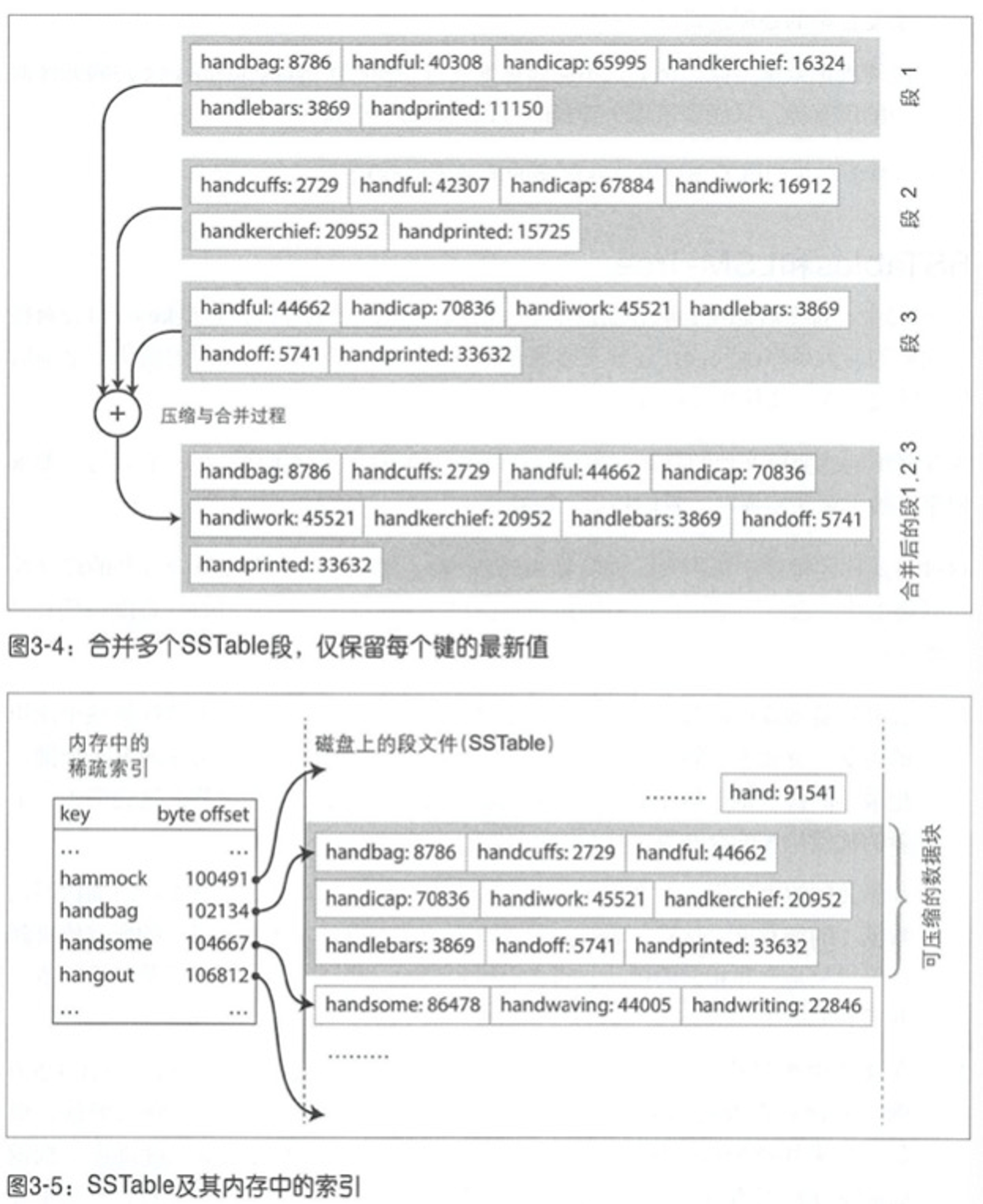
如果在前面数据文件格式基础上增加一个要求:让 kv 的顺序按照 k 来排序,这种格式称为 排序字符串表 Sorted String Table,它要求每个建在每个合并的段文件中只能出现一次,因为压缩是已经确保了。与前面的日志段合并相比有如下改进:
- 合并段更加高效,可以并发读取多个输入段文件,把k顺序小的先取出来合并,如果多个段中有相同的k则留下最新段中的值。
- 索引不需要存储全部的k,索引可以构建的比较稀疏,而我们知道要查找的k在索引中哪个范围内,之后因为文本数据是有序的,在索引确定了大致范围后即可在数据文本中查找具体的kv值。
如果所有kv具有固定大小,则可以在分段文件上二分查找且完全不使用内存中的索引,但是实践中数据常常是可变的,如果没有索引的话很难确定一个key的具体位置。
这一点在 Redis 的ziplist 中有类似做法,ziplist 中每个节点称为 entry,entry 中包含三个属性, previous_entry_length 表示前一个节点的长度,encoding 表示当前节点的类型和长度,content 则是具体的数据内容,这样一来就可以支持存储变长的数据了,并且可以向前向后遍历。
SSTables 的构建和维护
为了保证写入到段中的数据是有序的,可以在内存中排序更方便,如使用树状数据结构,存储引擎工作流程:
- 写入时添加到内存中的平衡树数据结构中,如红黑树,此时这个树也称为内存表。
- 当内存表大于某个阈值时如几兆,将其作为 SSTable 文件写入磁盘,由于树已经是有序的了,写磁盘比较高效,新的 SSTable 成为数据库最新部分,当 SSTable 写磁盘时,写入可以继续添加到一个新的内存表。
- 读时,可以先在内存表中查找看,然后是最新的磁盘段文件,接着是次新的、以此类推,知道找到或没找到。
- 后台进程周期性执行段合并和压缩来合并多个段文件,并丢弃已被覆盖和删除的值。
这个方案可以很好地工作,但还有一个问题是如果数据库崩溃,最新的写入,即那些在内存表中但还未写入磁盘的数据将丢失,解决这个问题可以引入单独的日志文件,每次写入时都会立即追加到该日志中,这个日志就是用来崩溃后恢复内存表的,而每次 SSTable 成功写入磁盘时,相应的日志就可以丢弃了。
联想到这个处理方式跟 Elasticsearch 处理方式很类似,Elasticsearch 为了让写入的数据尽快的能够被索引到, Elasticsearch 会每秒钟打开一个新的 Lucene segment,进入到 segment 中的数据即可被检索,同时通过数据会写入到 translog 中,此时并没有落盘持久化。当 Lucene 的 segment commit 之后会将数据 fsync 持久化到磁盘,之后相应数据的 translog 会跟着删除。
从 SSTables 到 LSM-Tree
这个处理方式本质上正式 LevelDB 和 RocksDB 所使用的,最初这种索引结构是由 Patrick O'Neil 等人以日志结构的合并树 Log-Structured Merge-Tree 即 LSM-Tree 命名,它建立在更早期的日志结构文件系统之上。因此基于合并和压缩排序文件原理的存储引擎通常被称为 LSM 存储引擎。
LSM-Tree 的性能优化
当查询某个不存在的 k 时,LSM-Tree 可能会很慢,因为它需要先查询内存表,然后将段一直回溯访问到最久的段文件,这可能需要多次读盘。这里可以加入布隆过滤器来识别不存在的 key。
另外不同策略会影响 SSTables 压缩和合并时具体顺序和时机,常见的方式是大小和分层,LevelDB 和 RocksDB 使用分层压缩,HBase 使用大小分级,Cassandra 则同时支持两种压缩。大小分级压缩中较新较小的 SSTables被连续合并到较旧和较大的SSTables。在分层压缩中旧的数据被移动到单独的层级。
即使有许多细微的差异,但 LSM-Tree 的基本思想,即保存在后台合并的一系列 SSTable,却足够简单有效,及时数据集远大于可用内存,他仍然能够正常工作。由于数据按排序存储,因此可以有效执行区间查询,并且由于磁盘是顺序写入,LSM-Tree 可以支持非常高的写入吞吐量。
B-trees
与 SSTable 一样,B-tree 也保留按键排序的 kv 对,这样可以高效查询kv和区间查询,但与 SSTable 将数据库分解为可变大小的段不同,B-tree 将数据分解成固定大小的块 blocks 或页 pages,传统上大小为 4K(有时更大),页是内部读写的最小单元,这种设计更接近底层,因为磁盘也是以固定大小的块排列的。
每个页使用地址或位置标记,这样可以让页之间进行引用,类似指针,但指的是磁盘地址而不是内存地址。 B-tree 有一个根节点,每次查询都从这个根节点开始
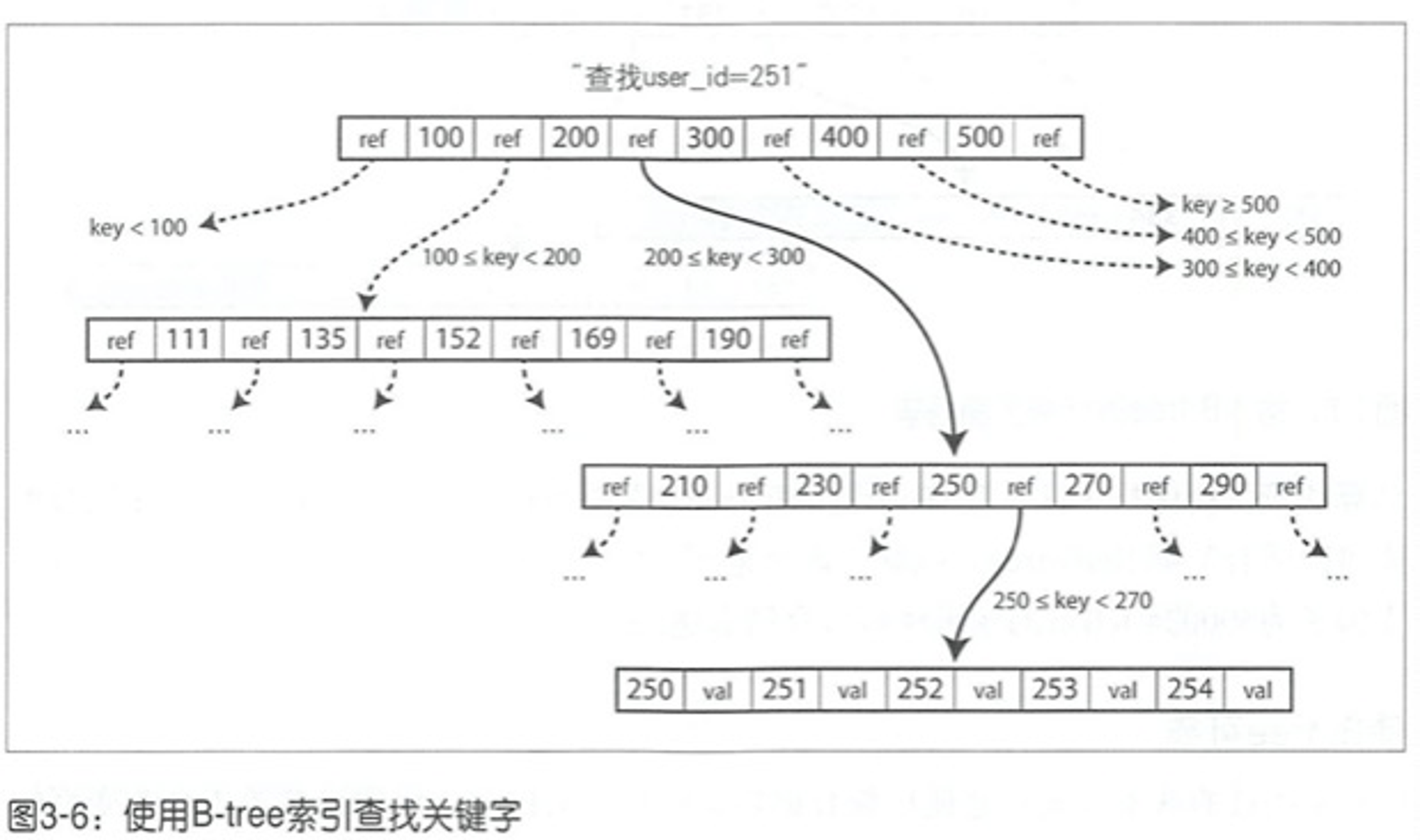
B-tree 中每个页所包含的子页引用数量称为分支因子,如上图为 6,即每一组 6 个数据。如果插入新节点后如果没有空间容纳新节点,旧的页将分裂为两个半满的页,且父页需要更新包含分裂后的新的键范围。
使 B-tree 更可靠,使用 WAL
B-tree 的修改是在原页上做覆盖,这与日志结构索引如 LSM-Tree 形成鲜明对比,LSM-Tree 仅追加更新文件而不会修改文件。而覆盖过程中涉及到很多步骤,如将磁头移动到正确位置,旋转扇面,覆盖相应扇区,如果遇到页分裂则可能会写多个页,这个过程中如果发生崩溃,索引可能会被破坏。
为了使数据库从崩溃中恢复,常见 B-tree 的实现需要支持磁盘上额外的数据结构:预写日志 write-ahead log WAL 即重做日志,这是一个仅支持追加的文件,每个 B-tree 的修改必须先更新 WAL 然后再修改树本身,在数据库崩溃后可以通过 WAl 对 B-tree 恢复到一致的状态。
原地更新另一个复制因素是多线程并发访问,这方面日志结构化的方法就更简单,因为在后台执行合并而不会干扰前端查询,并用新段原子替换旧段。
优化 B-tree
- 一些数据库不使用覆盖页和 WAL 进行崩溃恢复,而使用写时复制方案,修改的页被写入到不同位置,父页创建一个新版本并指向新的位置,这个做法对并发控制也有帮助。
- 保存键的缩略信息而不是完整信息,这样可以节省空间,这样可以留出空间压入更多的键,让树具有更高的分支因子,从而减少层数,例如 B+Tree。
- 尽量让相邻的页存储在相邻的磁盘位置上,这样有利于顺序大段扫描,但随着数据量增长维持这个顺序会越来越困难。
- 添加额外的指针,如在叶子页面可以向左向右指向同级兄弟页,这样可以顺序扫描键而不用跳回父页。
什么是写放大 write amplification
在数据库内,由于一次数据库写入请求导致的多次磁盘写被称为写放大(write amplification)。对于 SSD 由于只能承受有限次的擦除覆盖,因此尤为关注写放大指标。
对比 LSM-Tree 和 B-tree
LSM-Tree 通常写入更快,而 B-tree 读取更快,在 LSM-Tree 上读取相对较慢,因为它必须在不同的压缩阶段检查多个不同的数据结构和 SSTable。
优点1:较低的写放大
很多性能瓶颈很可能在于数据库写入磁盘的速率,所以降低写放大就尤其有意义了。LSM-Tree 通常能够承受比 B-tree 更高的写入吞吐量,就是因为其具有较低的写放大,部分原因是由于其以顺序方式写入紧凑的 SSTable 文件而不必重写树中的多个页,这种差异对磁盘尤为重要,因为磁盘顺序写比随机写要快得多。
优点2:更少的碎片
由于 LSM-Tree 支持合并压缩以消除碎片,这一点对于 B-tree 其固定大小的页有时无法满足数据的大小时,剩余空间将无法使用。
缺点1:压缩干扰读写
有时压缩过程会干扰正在进行的读写操作。由于磁盘进行昂贵的压缩操作时容易发生读写请求等待的情况,如果观察 TP-90 等较高百分位数有时会看到延迟相当高。而 B-tree 的响应延迟更具确定性。
缺点2:压缩速率低于写入速率造成磁盘空间耗尽
如果写入吞吐量很高,并且压缩没有仔细配置,压缩跟不上写入速率。在这种情况下,磁盘上未合并段的数量不断增加,直到磁盘空间用完,读取速度也会减慢,因为它们需要检查更多段文件。
其他索引结构
在索引中存储值
索引中的值可能是实际的行,也可能是其他的引用,如 InnoDB 存储引擎中,表主键始终都是聚集索引,二级索引引用主键。
聚集索引与非聚集索引之间有一种折中设计称为覆盖索引或叫包含列的索引,其在索引中保存一些表的列值,在一些简单查询时可以直接从索引中查到结果。但每种索引对读加快速度的同时都会对写入有影响。
多列索引
以上都是在单一维度上建立的索引,多列索引即在多个维度上做检索时起到作用,经纬度在一定范围内的餐馆。
全文搜索和模糊索引
如 Elasticsearch 的模糊检索需要计算一个 levenshtein distance 莱文斯坦距离,指两个字串之间,由一个转成另一个所需的最少编辑操作次数。 允许的编辑操作包括: 将一个字符替换成另一个字符、插入一个字符、删除一个字符。一次编辑在距离上做 +1,通过设置阈值来限制召回的结果。
在内存中保存所有内容
如 memcached,还有一些在内存存储之外提供较弱的持久性,如 Redis Couchbase等。
与直觉相反,内存数据库性能优势并不是因为他们不需要从磁盘读取,如果有足够内容,即便是基于磁盘的存储引擎也可能永远不需要从磁盘读取,因为操作系统将最接使用的磁盘块缓存在内存中。相反,内存数据库之所以更快,原因在于省去了将内存数据结构编码为磁盘数据结构的开销。
事务处理与分析处理
事务处理 OLTP 和分析处理 OLAP 特性比较:

- OLTP:面向用户,可能收到大量请求,应用每次只取少量记录,磁盘寻道时间往往是瓶颈,即找到数据的位置。
- OLAP:面向业务分析,请求数较低,但是需要短时间内扫描百万条记录,磁盘带宽通常是瓶颈。
数据仓库
将数据导入到数据仓库的过程称为提取-转换-加载 Extract-Transform-Load ETL。仓库中一个实体可以按不同维度单独建立维度表,代表对象的属性,如地点、时间等等。
列式存储
在大多数 OLTP 中,存储以面向行的方式布局,来自表的一行的所有值彼此相邻存储。文档数据库也类似,整个文档通常被存储为一个连续的字节序列,类似前面的 CSV 格式数据库,每一行收尾相连。
而面向行的存储将每列中所有值存储在一起,如果每个列存储在一个单独的文件中,查询只需要读取和解析在该查询中使用的那些列,这会节省很大工作。
列压缩
在列存储中对于一列数据可能会有很多重复值,可以根据重复值的特点做压缩,如果值只存在有限的几个可选值则使用位图来替代,接着如果位图中大部分都是 0,即它们很稀疏,则可以使用游程编码 run-length encoding RLE 来进一步压缩。
游程编码简介:举例来说,一组资料串"AAAABBBCCDEEEE",由4个A、3个B、2个C、1个D、4个E组成,经过变动长度编码法可将资料压缩为4A3B2C1D4E(由14个单位转成10个单位)。
简言之,其优点在于将重复性高的资料量压缩成小单位;然而,其缺点在于─若该资料出现频率不高,可能导致压缩结果资料量比原始资料大,例如:原始资料"ABCDE",压缩结果为"1A1B1C1D1E"(由5个单位转成10个单位)。
列存储的写操作
方面向列的存储压缩和排序都有助于查询,而缺点则是让写入变得困难。可以参考前面 LSM-Tree 的做法,在内存中存储排序,在达到一定条件之后与磁盘上列文件合并,批量写入。
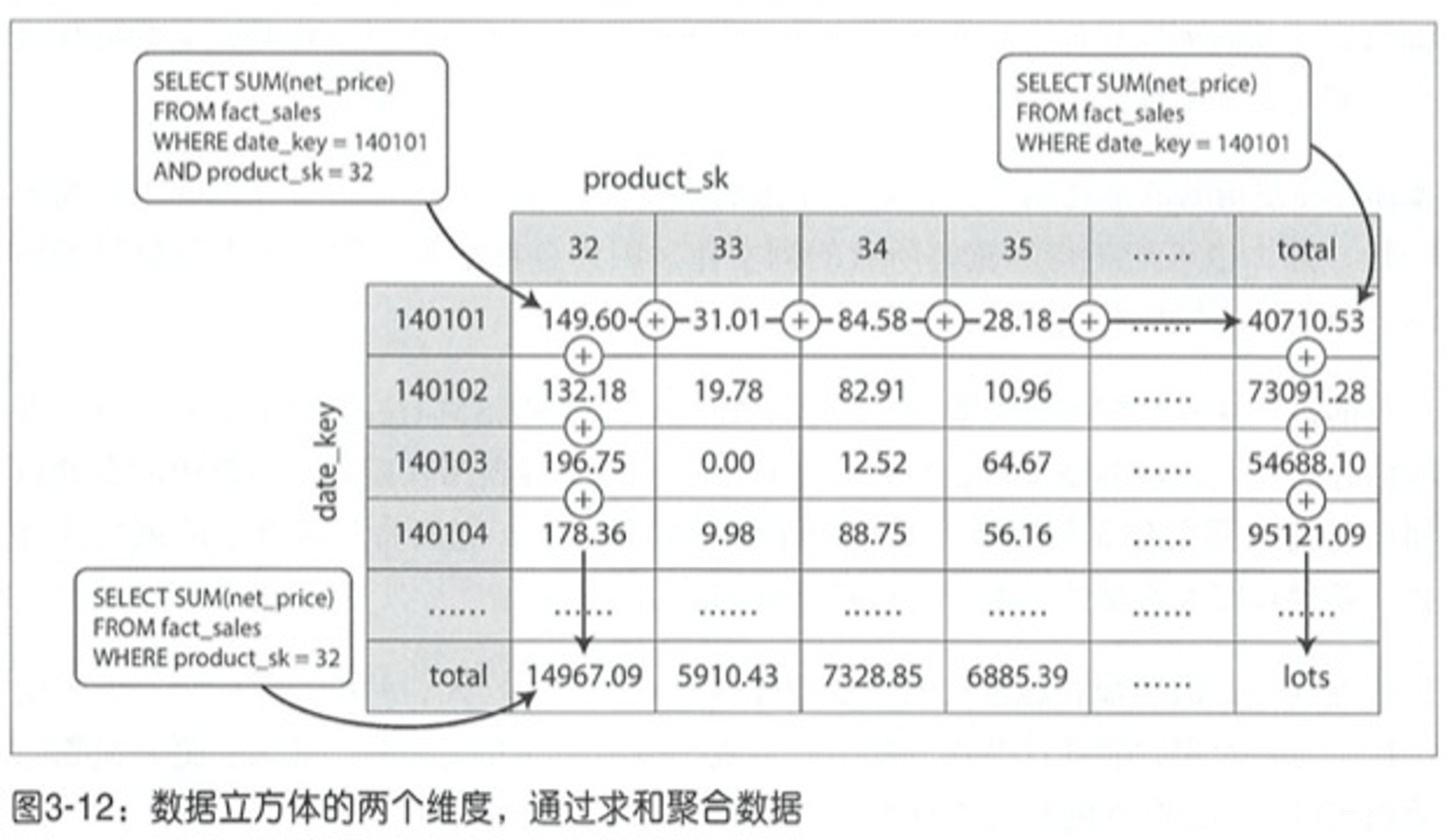
聚合:Data Cubes 和 Materialized Views
基本思路就是提前算好数据,查的时候直接用。Data Cube 是沿着某一维度做聚合,得到一个减少一个维度的总和:
OLTP 存储引擎日志流派和原地更新流派
- 日志结构流派:只允许追加式更新文件和删除过时的文件,但不会修改已写入的文件,Bitcask、SSTables、LSM-Tree、LevelDB、Cassandra、HBase、Lucene 都属于此类。
- 原地更新流派:将磁盘视为可以覆盖的有一组固定大小的页。B-tree 是这一哲学的最经典代表,他已用于所有主要的关系数据库,以及大量的非关系数据库。