数据密集型应用系统设计-数据分区
date
Dec 10, 2021
slug
reading-notes-ddia-sharding
status
Published
tags
读书
系统和网络
summary
type
Page
分区也称分片。
键-值数据的分区
分区如果不均匀,则会出现某些分区节点比其他分区承担更多的数据量或查询负载,称之为倾斜。负载不成比例的分区称为系统热点。
基于关键字区间分区
为每个分区分配一段连续的关键字或者关键字区间范围。这种分区方式容易产生热点和数据倾斜,因为每个连续区间的读写概率不一样。进而导致数据量有的大有的小。
优点是支持高效区间查询,缺点是容易出现热点分区。
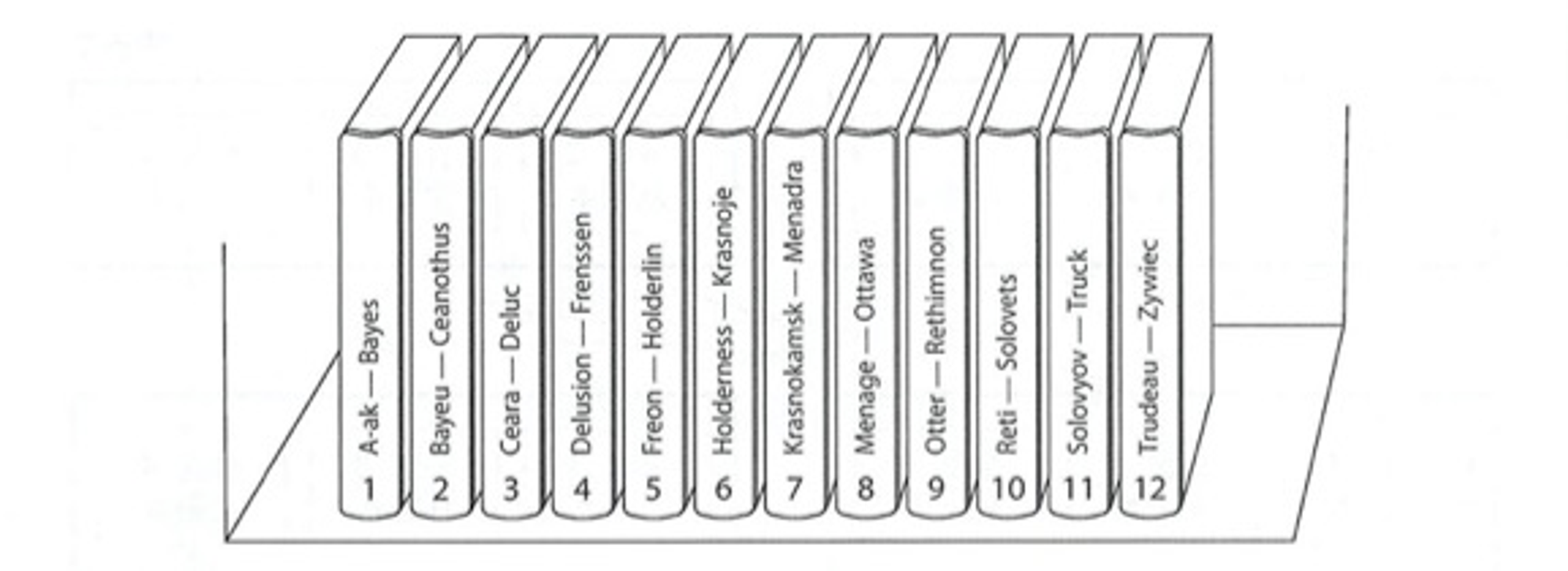
基于关键字哈希值分区
注意是将key的哈希值划分一个区间,而不是直接将哈希值映射到节点上。具体来说此方法要求哈希值必须是数值型,之后在数值型哈希值上做区间划分。
哈希值分区优点是避免上面的热点和数据倾斜问题,使集群数据更加均匀,缺点是丧失了区间查询的特性。
负载倾斜与热点问题
例如社交媒体上名人粉丝百万,发布一些热点事件可能引发一场访问风暴,出现大量对相同关键字的写操作。
分区与二级索引
二级索引通常不能唯一标识一条记录,而是用来加速特定值的查询。二级索引主要挑战是他们不能规整的映射到分区中。也就是说:数据本身是分区了的,那么数据相应的二级索引应该怎么存储的问题。
基于文档分区的二级索引 - 本地索引
即按照现有文档所在的分区各自维护二级索引,故也称为本地索引。
这种方式中每个分区相互独立,各自维护自己的二级索引,且自负责自己分区中的文档而不关心其他分区中的数据。如图分区0和1都各自维护了自己的红色汽车和 Ford 厂商索引。
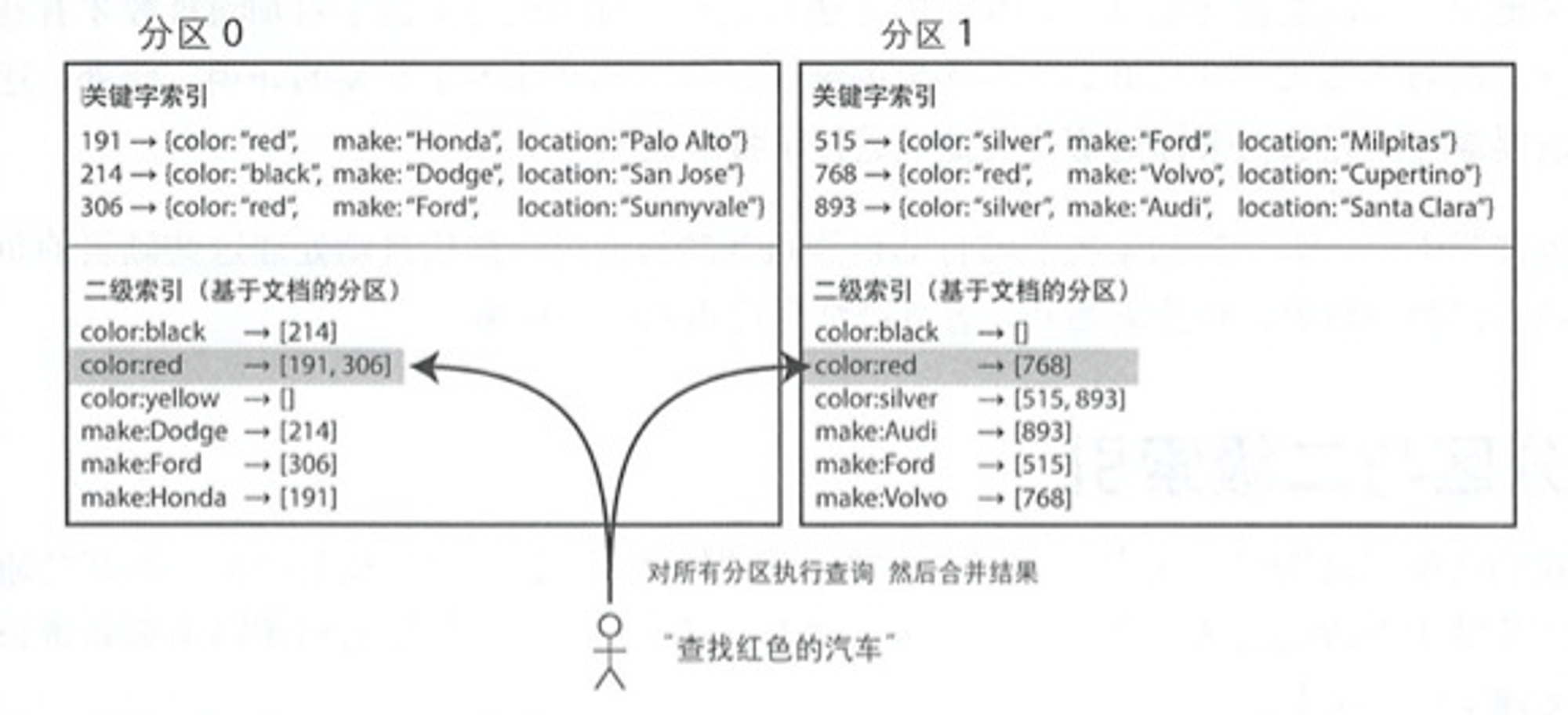
这种方式问题是如果想要查询所有的红色汽车,则需要去所以分区中查询,在合并所有分区返回的结果。这种方式称为 分散/聚合,显然这种查询方式代价较高。即使采用并行查询也容易导致读写延迟显著放大。尽管如此实践中还是很多在用,如MongoDB、Elasticsearch 等待。
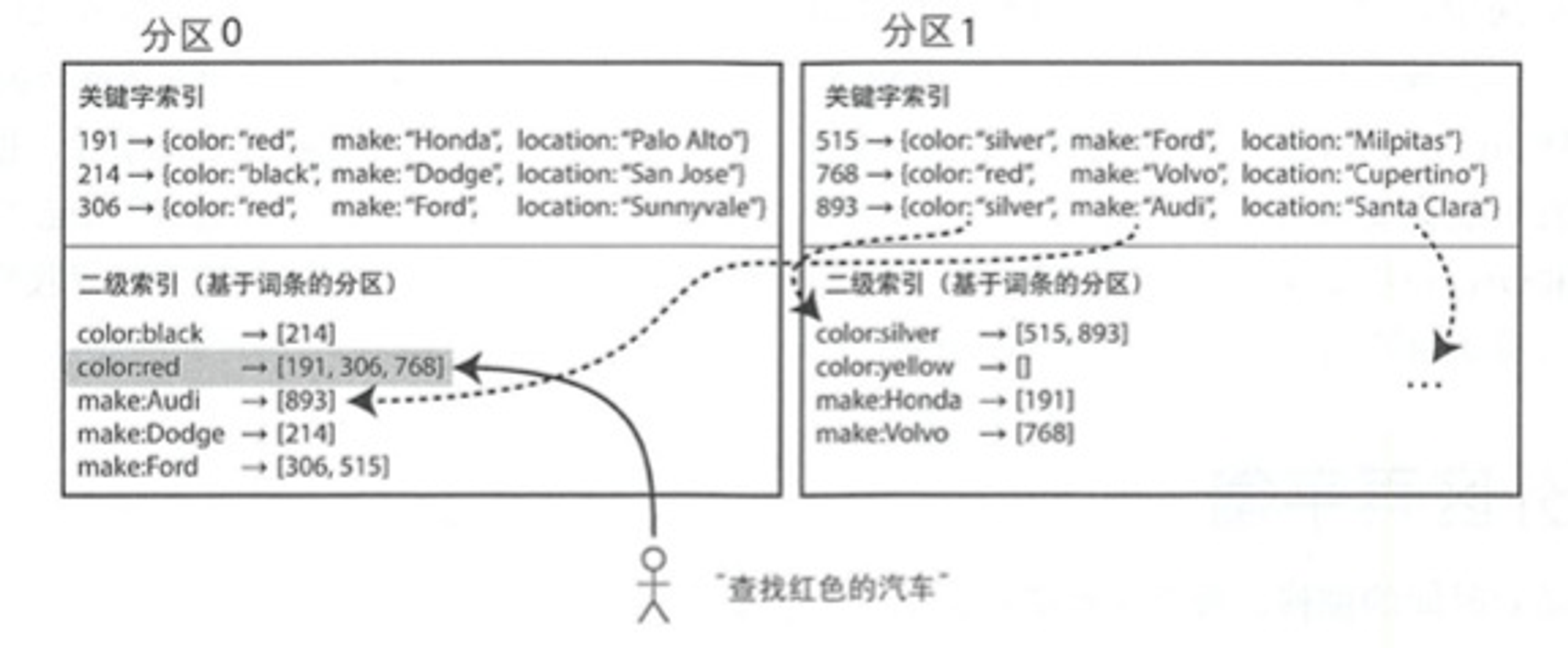
基于词条的二级索引分区 - 全局索引
即按照查询的词条来划分二级索引,同时将其分布在分区中,称为全局索阳引。
这样一来同一索引字段可以固定在一个分区中,查询时就可以只在一个分区中查询。
两种二级索引方式比较
本地索引优点是读写只关心当前分区,实现简单。缺点是需要跨分区查询。
全局索引优点是读取更高效,只在一个分区查询即可,缺点是写入时速度较慢,而且索引跟数据可能不在一个分区上,如果涉及到多个索引则代价更大。而且全局索引会存在跨分区更新索引事务问题,如果同步更新索引势必代理性能问题,所以必须在一致性和可用性上做出取舍。实践中更新二级索引往往都是异步的。
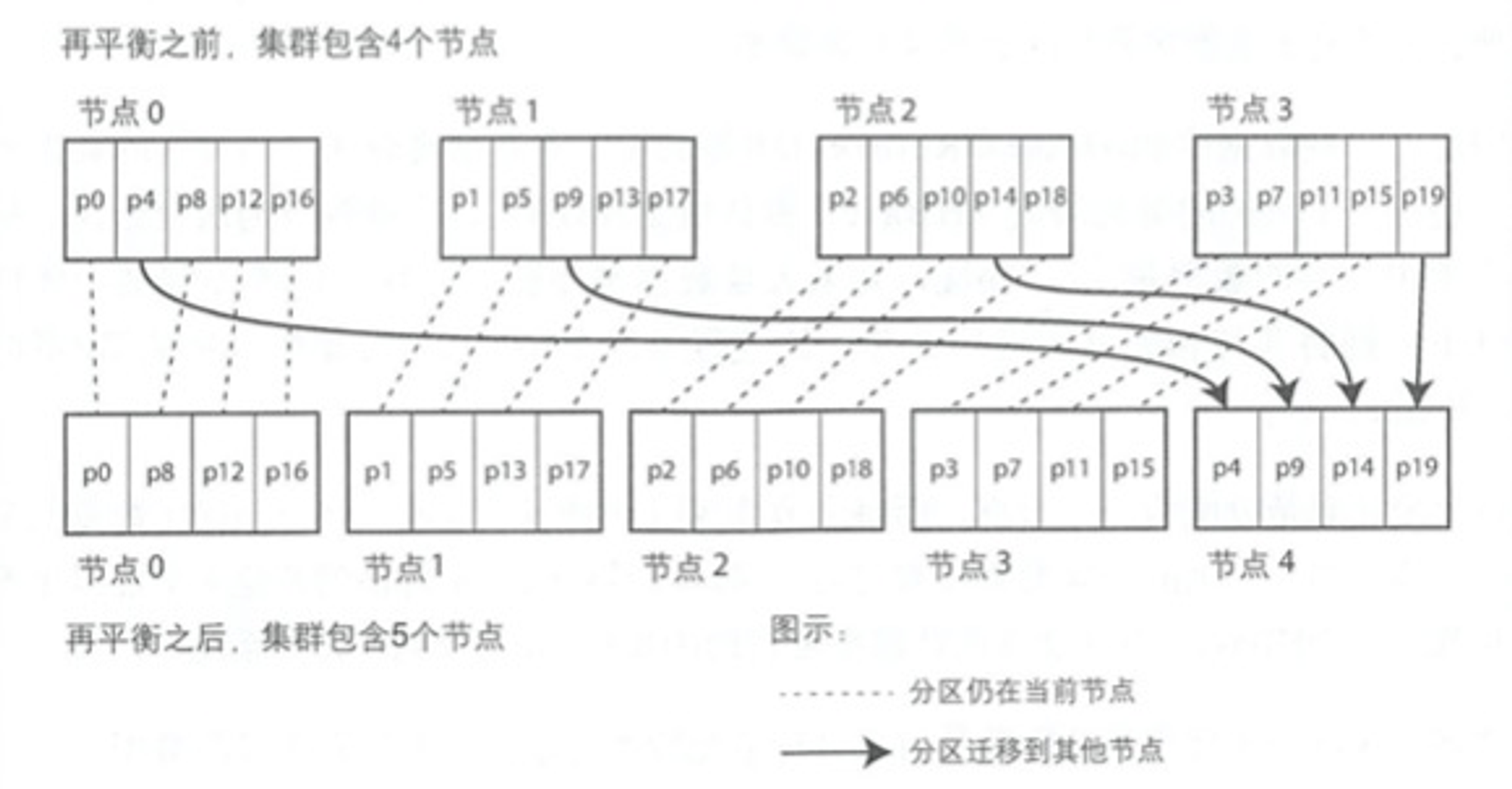
分区再平衡
将数据和请求从一个节点转移到另一个节点的迁移称为再平衡。
分区时为什么不用取模?
前面基于哈希值区间划分中,为什么不直接使用mod(key) 到节点的映射?
如果一开始节点数是10,mod10=6,即节点6,如果增加节点数量至11个,那么mod11=3,则需要将原来的key迁移到节点3,如果再次增加节点数量就会再次出现迁移,大大增加再平衡成本。减少迁移数据成本是主要考虑的。
固定数量的分区
一个简单的方案是预先分配远超实际的分区数,每个节点负责很多个分区。如10个节点的集群中创建1000个分区,每个节点负责100个分区。如果集群中有节点变化,则从每个节点中匀走几个分区。这种策略要求数据库在创建时就要确定好分区数量,以后不会改变。Elasticsearch、CouchDB 等都支持这种动态平衡。
动态分区
一些数据库如 HBase RethinkDB 支持动态分区,当分区数量超过一个可配参数阈值,就会拆分成两个分区,如果大量数据被删除至分区缩小到某个阈值,则将其与相邻分区合并,类似于 B-tree 的分裂操作。
按节点比例分区
Cassandra 和 Ketama 采用第三种方式,使分区数与集群节点数成正比关系,即每个节点有固定数量的分区。
请求路由
即当客户端发送请求时如何知道应该连接哪个节点?如果发生了再平衡分区与节点的关系还会变化。这属于服务发现问题,服务发现不限于数据库,任何通过网络访问的系统都有这种需求,尤其是服务目标支持高可用时(在多台机器上有冗余配置)。
概括来讲有三种处理策略:
- 允许客户端连接任意节点,如果某节点恰好拥有请求的分区,则直接处理请求,否则将转发请求到下一个合适的节点。
- 将所有客户端请求发到一个路由层,由后者负责将请求转发到对应分区节点。路由层不处理任何请求,只是一个分区感知的负载均衡器。
- 客户端感知分区和节点分配关系,客户端可以直接连接到目标节点,而不需要任何中介。
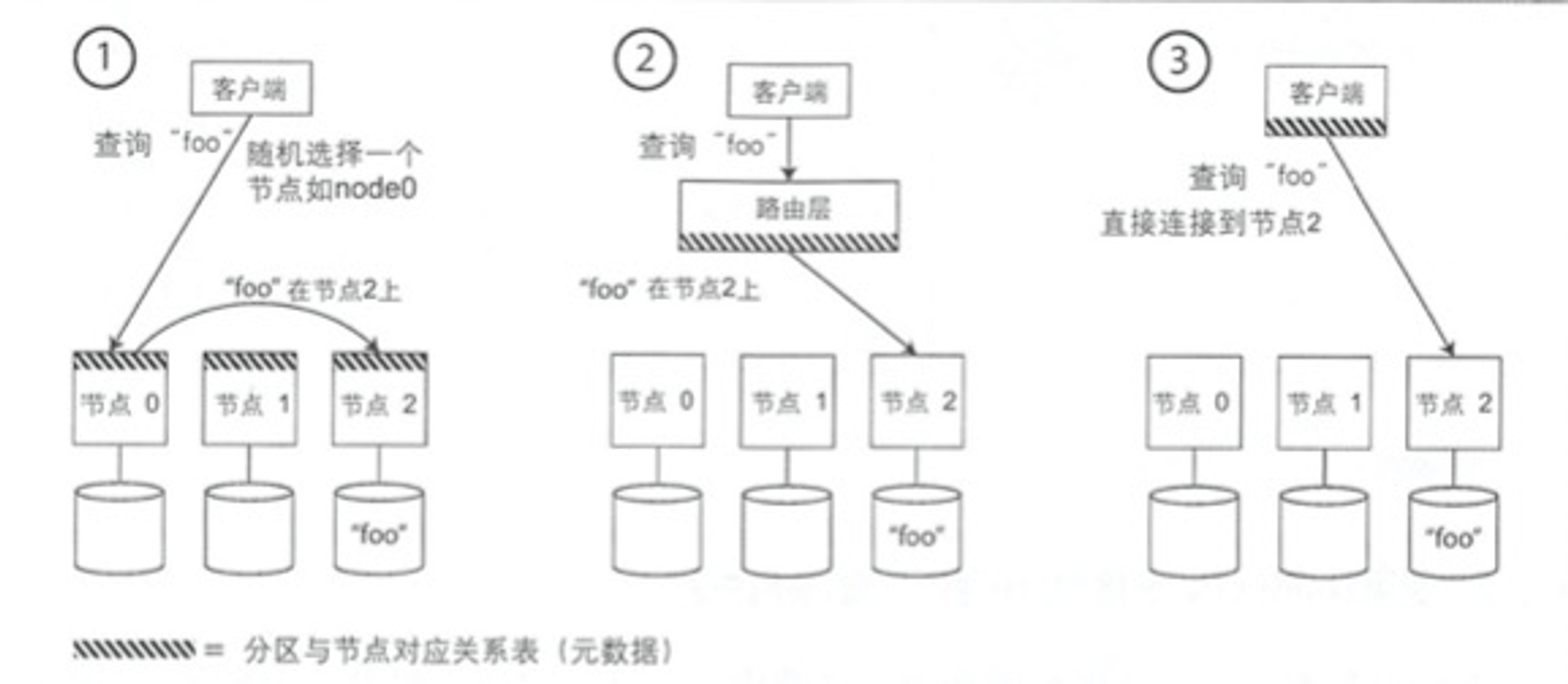
不论哪种方法,核心问题是:做出路由决策的组件(可能是某个节点、路由层或客户端)如何知道分区与节点的对应关系以及其变化情况?
这其实是一个很有挑战性的问题,所有参与者都要达成共识这一点很重要。许多分布式数据系统依靠独立的协调服务跟踪集群范围内的元数据。如 zookeeper。每个节点向zookeeper注册自己,zookeeper维护了了分区到节点的最终映射关系。其他参与者如路由层或客户端可以向zookeeper订阅此信息,一旦分区发生改变,添加或删除节点,zookeeper会主动通知参与者,保持最新状态。

并行查询执行
大规模并行处理 massively parallel processing MPP,主要用于数据分析的关系数据库,在查询类型方面要复杂得多。