数据密集型应用系统设计-数据编码与演化
date
Dec 10, 2021
slug
reading-notes-ddia-encoding-and-evolution
status
Published
tags
读书
系统和网络
summary
type
Page
应用程序不可避免的随时间变化,相应的数据也会随之变化。发布新版本时对于服务端来说可能会通过滚动发布,一部分一部分的更新代码,对于客户端来说取决于用户什么时候更新软件。总之是会存在新旧版本共存的情况,这就涉及到新旧版本兼容问题。
数据编码的格式
程序的数据一般分两种表示形式:
- 在内存中,如对象、结构体、列表、数组、哈希、树等结构,这些数据结构针对 CPU 高效访问做了优化。
- 在磁盘文件或通过网络发送出去,这要求数据必须被编码成某种自包含的字节序列,所以也叫序列化。
语言内置编码→JSON、XML→二进制编码
许多语言内置支持将内存中的数据编码成字节序列,者称为序列化,反之称为反序列化,如 Java 的 java.io.Serializable Python的pickle等,但这有个缺点,使用这种编码就意味着编解码两端必须使用同一种语言。所以应用更多的是通用编码方式,JSON xml 等。
但JSON和XML这种空间占用太多,如果使用二进制来编码就更加紧凑来了。这种观察导致开发出了大量的二进制编码,如 MessagePack、BSON、BJSON、UBJSON、BISON和Smile等, 同样 XML 也有WBXML、Fast Infoset 等。
二进制编码
MessagePack
拿 MessagePack 来说,对于 JSON:
经过 MessagePack 编码后得到:
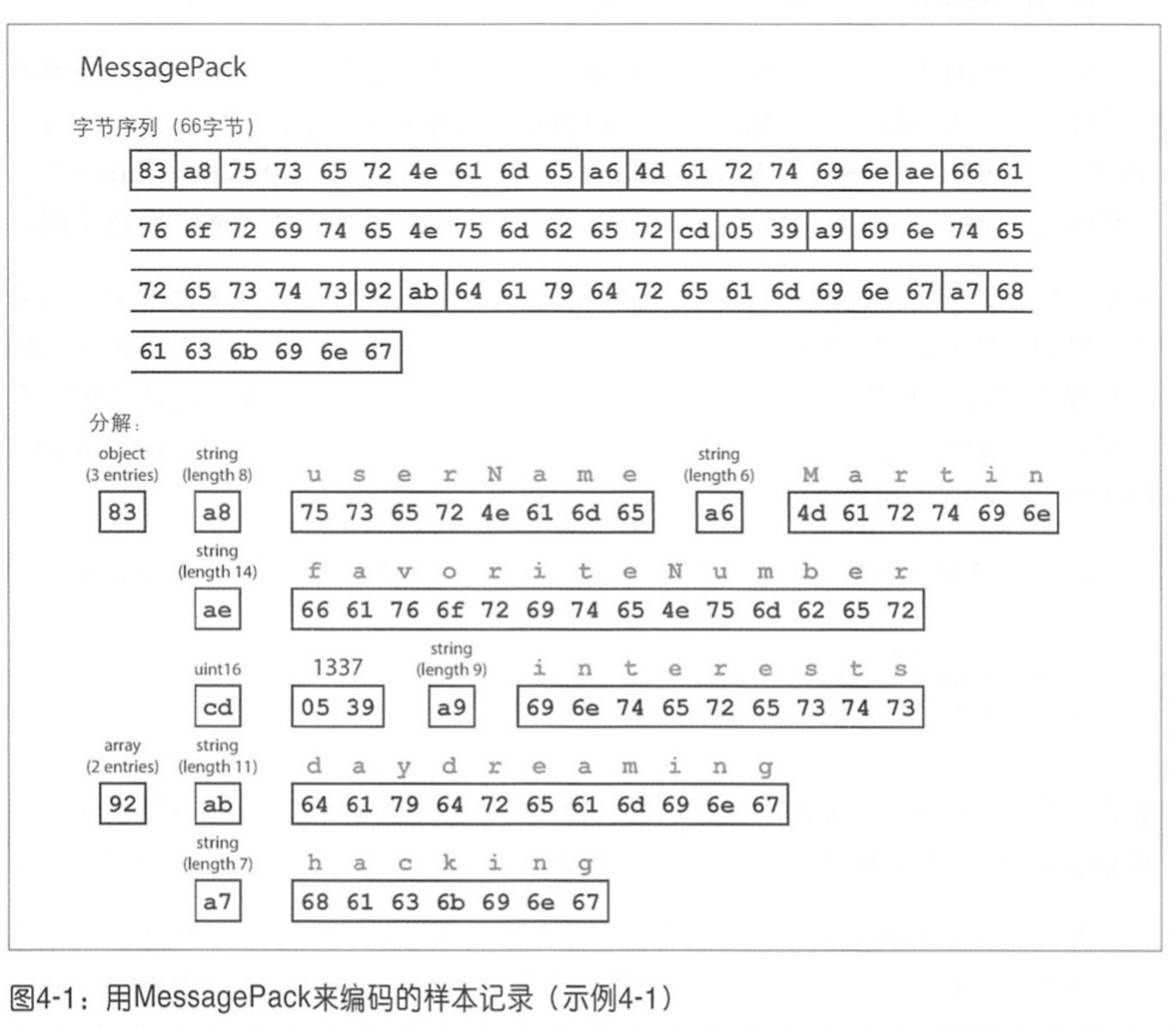
思想就是通过一些标记位来标示出紧接在后面的字段什么类型、长度多少。经过编码后一共占用 66 字节,而原始 JSON 长 81 字节,确实节省了一些但并没有太多。
Thrift 和 Protocol Buffers
延续这个思路可以进一步压缩空间,例如 Facebook 的 Thrift 和 Google 的 Protocol Buffers 编码,两者都是在 2007-2008 年开源的,而且两者使用方式也很相似,首先定义模式:
Thrift:
Protocol Buffers
Thrift 有两种编码格式,BinaryProtocol的结果如下:
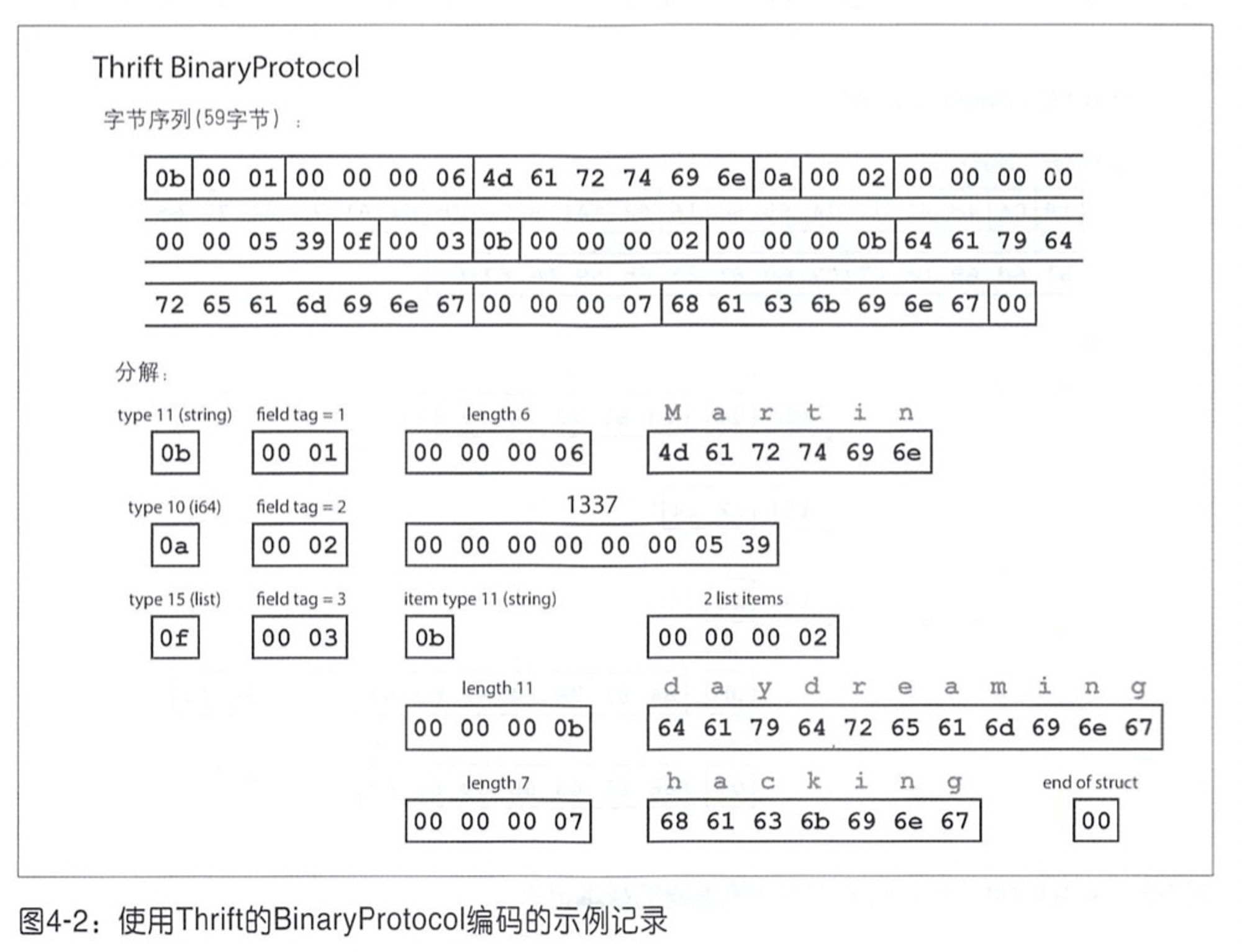
而用 CompactProtocol 编码格式结构如下:
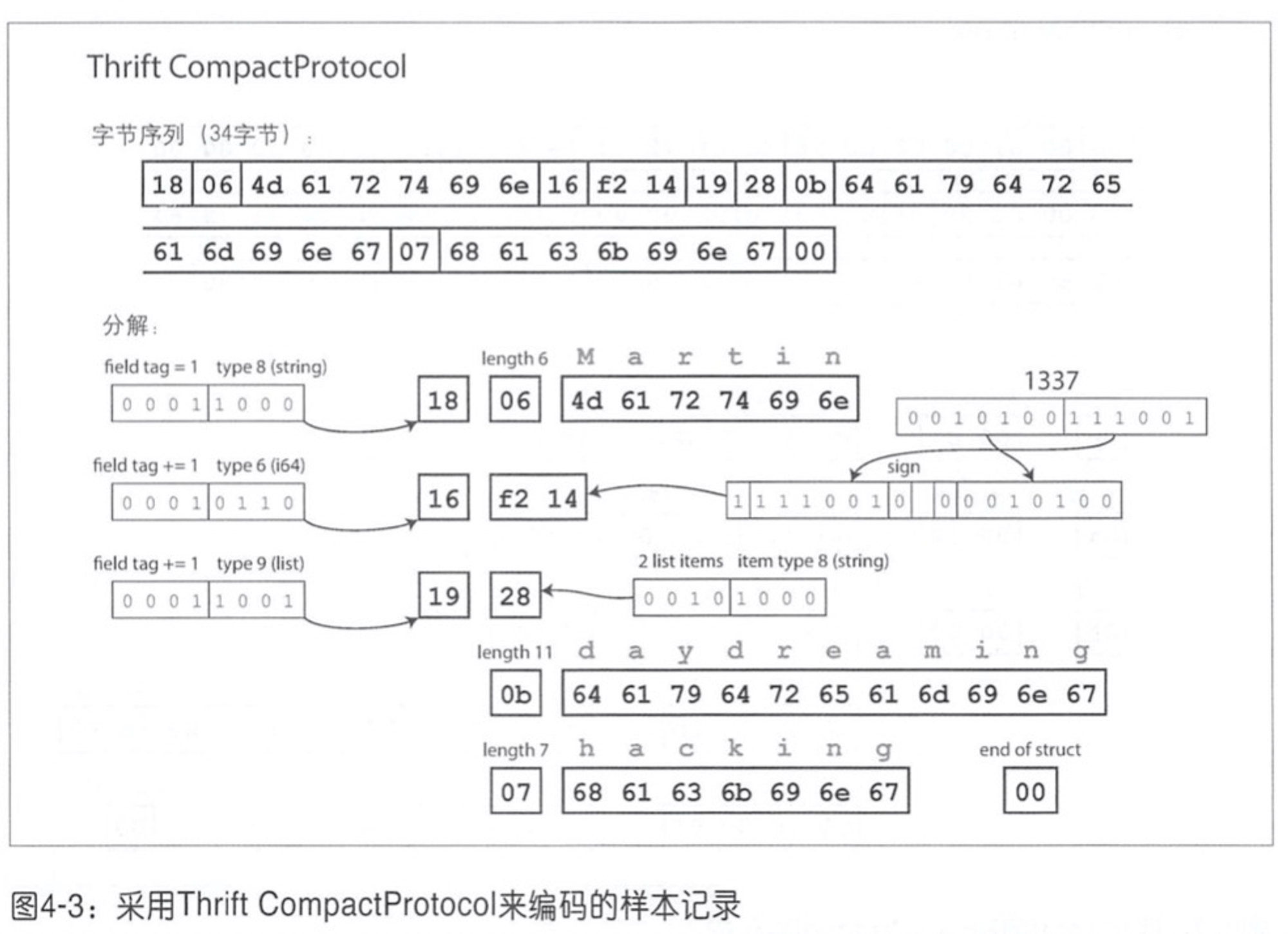
使用 Protocol Buffers 编码:
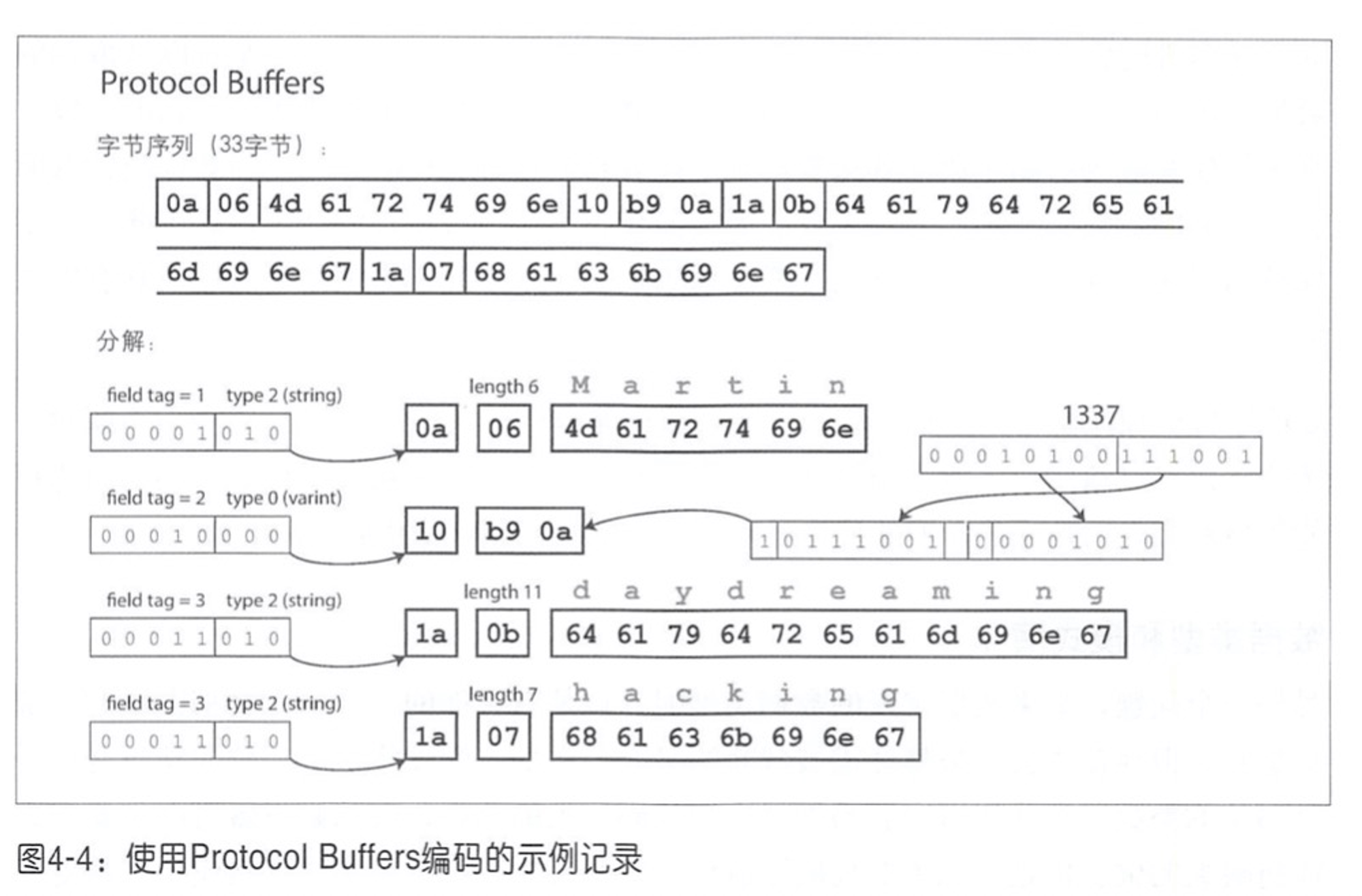
可以看到沿用 MessagePack 那种二进制紧凑编码的思路,加上使用 field tag 的方式替代掉原有的字段名,节省了不少空间。
那么如果保证新旧版本兼容?因为两者通过 field tag 指代具体字段,所以只要 field tag 不变,其具体内容是什么无所谓,另外可以顺延新增 field tag 这样旧版本接到会忽略不会报错,新版本接到就正常识别。
Avro
与 Thrift 和 Protocol Buffers 类似的还有 Avro,由于 Thrift 不适合 Hadoop 的用例,所以 Avro 在 2009 年作为 Hadoop 子项目启动。其模式定义跟前两者很像,不过并没有 field tag:
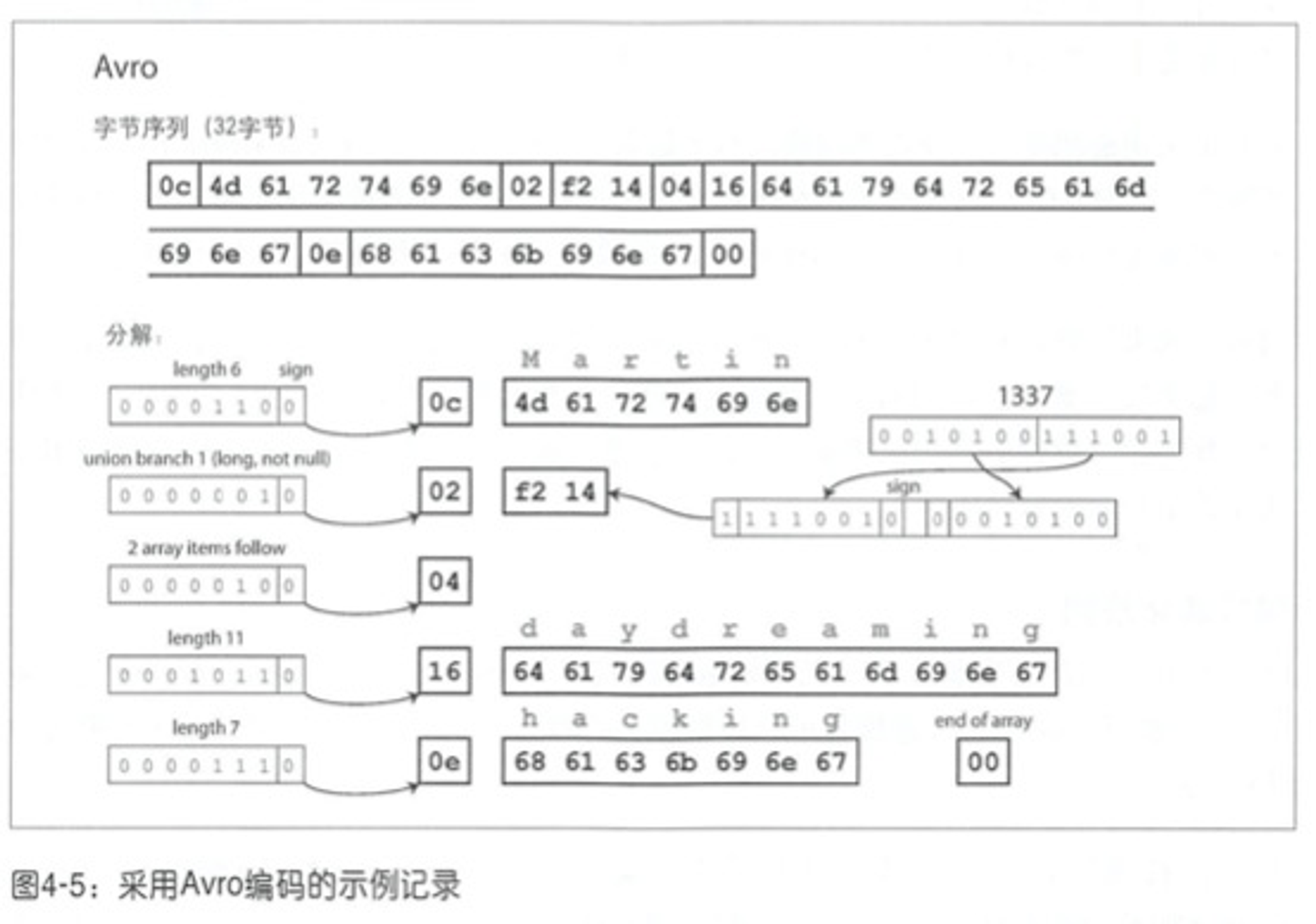
所有值都是连在一起的。
二进制模式的优点
编码格式有文本形式的 JSON、XML、CSV,也有如上面的二进制形式的 Thrift、Protocol Buffers、Avro,二进制格式的优点是:
- 它们可以比各种二进制 JSON 变体更紧凑,比如 MessagePack,可以省略编码数据中的字段名。
- 因为模式是解码所必须的,所以可以确定每一次迭代改版,模式都是最新版的,因为不是最新版解码时就会有问题。
- 模式允许检查向前和向后兼容性。
- 对于静态类型语言来说,可以通过模式来生成代码,这样可以在编译时进行类型检查。
数据流模式
数据可以通过多种方式从一个进程流向另一个进程:
- 通过数据库:一个进程插入数据,另一个进程查询数据,这两个进程也有可能是同一个进程。
- 通过服务调用:RPC 调用试图使调用远程服务看起来与调用本地方法一样,但实际上网络请求和本地函数非常不同。
- 通过异步消息传递