数据密集型应用系统设计-分布式系统的挑战
date
Dec 10, 2021
slug
reading-notes-ddia-challenge-of-distributed-system
status
Published
tags
读书
系统和网络
summary
type
Page
故障与部分失效
要使分布式系统可靠工作,就必然面临部分失效,这就需要依靠软件系统来提供容错机制。换句话说,我们需要在不可靠的组件上构建可靠的系统。
故障处理是软件设计的重要组成部分。作为系统运维者,需要知道在发生故障时,系统的预期行为是什么。
不能假定故障不可能发生而总是期待理想情况。最好仔细考虑各种可能的出错情况,包括那些小概率故障,然后尝试人为构造这种测试场景来充分检测系统行为。可以说在分布式系统中,怀疑,悲观和偏执狂才能生存。
不可靠的网络
超时与无限期的延迟
当一个节点被宣告为失效,其承担的职责要交给到其他节点,这个过程会给其他节点以及网络带来额外负担,特别是如果此时系统已经处于高负荷状态。
网络拥塞与排队
计算机网络上数据包延迟的变化根源往往在于排队:网络交换机会出现排队,到达目标机器后,操作系统会将数据包进行排队,还有如 TCP 拥塞控制,这意味着数据进入网络之前就已经在发送方开始了排队。
同步与异步网络
资源静态和动态分配
电路交换和分组交换区别在于,前者会预留带宽,传输稳定且速度快,但链路整体利用率低。后者会出现排队现象,但链路整体利用率高。
当资源是静态分配,如预留,则可以保证延迟的确定性。
但如果是以提高资源利用率为目的,则动态资源分配更合适。
同样的例子还出现在多个线程动态共享 CPU 核,也是通过排队来实现整体利用率的最大化。
简言之,网络中的可变延迟并不是一种自然规律,只是成本与收益互相博弈的结果。
不可靠的时钟
单调时钟与墙上时钟
墙上时钟即时间戳所指的时间,是一个具体的真实存在的时间。单调时钟的名字则源于它们保证总是向前,而不会出现像墙上时钟的回拨现象。
注意单调时钟的绝对值没有任何意义,只是用来计算差值。
依赖同步的时钟
时间戳与事件顺序
跨节点的事件排序,如果它高度依赖时钟计时,就存在一定技术风险。如两个客户端同时写入分布式数据库,谁先到达?哪一个操作是最新的呢?
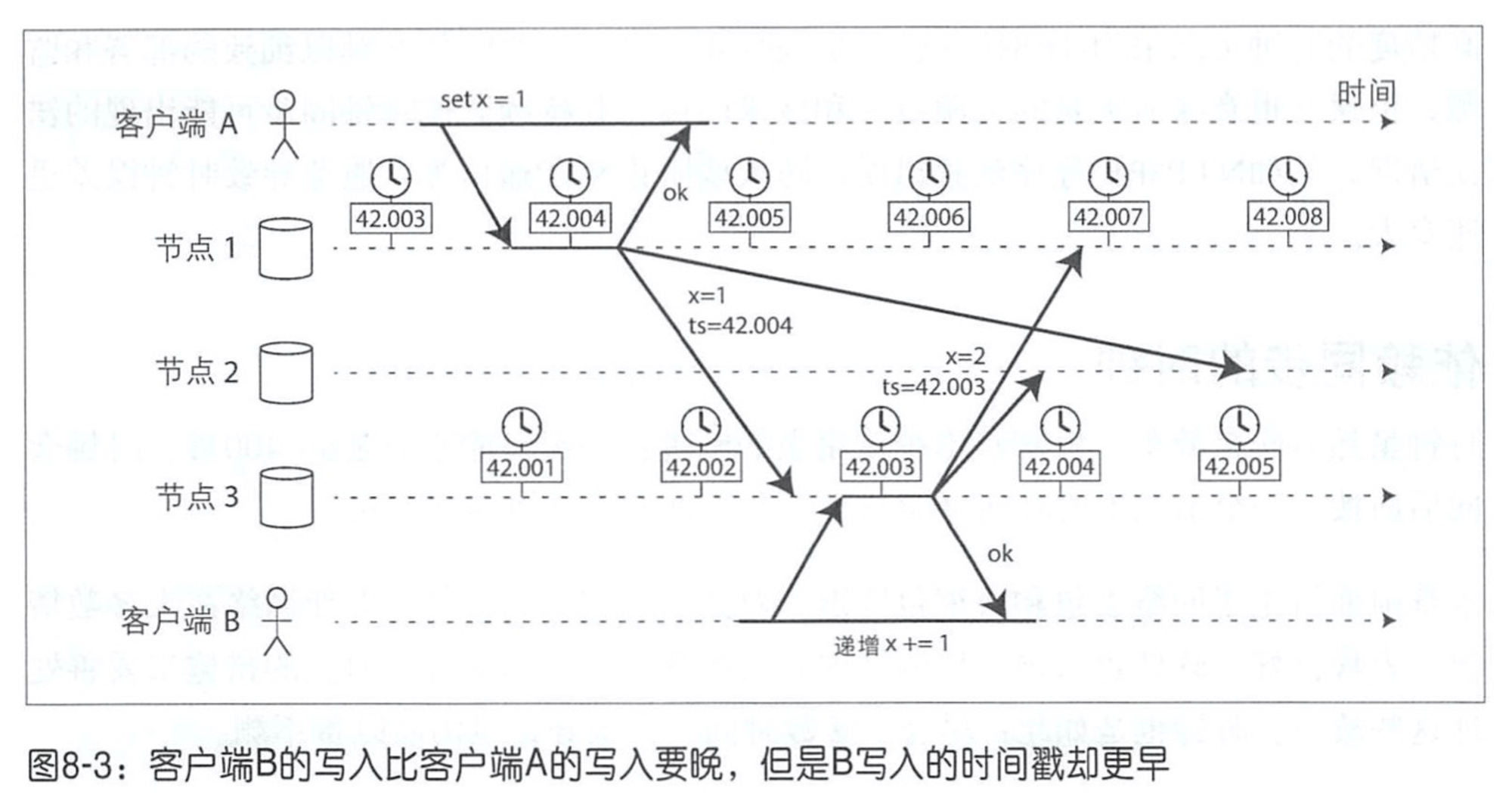
图中客户端 B 的写入明明发生在客户端 A 之后,但由于 B 的时钟太快了,发生在 42.003s,而 A 发生在 42.004s 时,所以根据发生时间来看,就是 B 先发生了,最终导致后写入的数据被覆盖掉。
这种冲突解决策略被称为最后写入获胜 LWW 。
时钟的置信区间
Google Spanner 中的 TrueTime API 会明确地报告本地时钟的置信区间。当查询当前时间时,会得到两个值,[不早于, 不晚于],分别代表误差的最大偏差范围。
全局快照的同步时钟
常见的快照隔离实现中需要单调递增事务 ID。如果写入发生在快照之后,即写入具有比快照更大的事务 ID,那么该写入对快照不可见。在单节点数据库上一个简单的计数器足以生成事务 ID。
但当数据库分布在多台机器上,可能跨越多个数据中心时,由于需要复杂的协调以产生全局的、单调递增的事务 ID (并且是跨所有分区的)。事务 ID 要求必须反映因果关系,即事务 B 如果要读取事务 A 写入的值,则 B 的事务 ID 必须大于 A 的事务 ID,否则快照将不一致。考虑到大量、频繁的小数据包,在分布式系统中创建事务 ID 通常会引入瓶颈。
进程暂停
进程可能随时暂停,再恢复时早已物是人非。
总之你不能假定任何有关时间的事情,记住上下文切换和并行性可能随时可以发生。
分布式系统中的一个节点必须假定,在执行过程中的任何时刻都可能被暂停相当长一段时间,包括运行在某个函数中间。暂停期间,整个集群的其他部分都在照常运行,甚至会一致将暂停的节点宣告为故障节点。最终,暂停的节点可能会回来继续运行,除非再次检查时钟,否则它对刚刚过去的暂停毫无意识。
知识,真相与谎言
真相由多数决定
许多分布式算方法都依靠法定票数,quorum。分布式系统中所有个体节点必须遵循法定投票的决议,如法定票数宣告某节点失效,即使节点本身存活着,也必须遵守决议并离线。
由于系统中只可能存在一个多数,绝不会有两个多数在同时做出相互冲突的决定,所以系统的决议是可靠的。
主节点与锁
很多情况下系统范围内只能有一个实例:
- 如只允许一个节点作为分区主节点,防止出现脑裂。
- 如只允许一个事务或客户端持有特定资源的锁,防止同时写入从而导致数据破坏。
- 如只允许一个用户使用特定的用户名,确保用户名唯一。
但在分布式系统实现时要额外注意,有些节点会自以为是“唯一的那个”。可能他原来确实是主节点,但其他节点可能在此期间宣布其失效。
如果系统设计不周就会出现负面后果,该节点会自认为正确的向其他节点发送信息,而如果其他节点还选择相信,那么系统就会出现错误的行为。
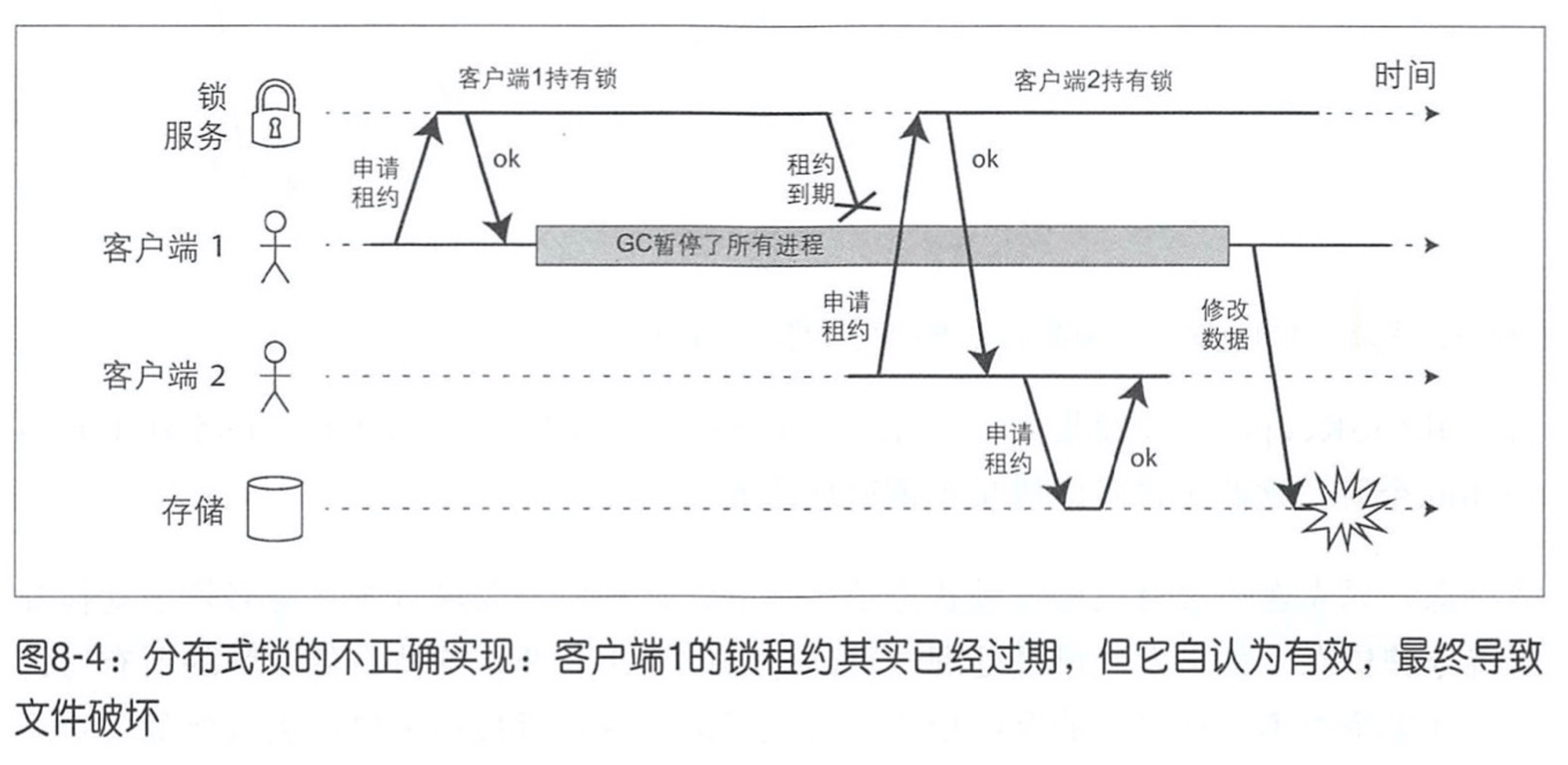
如图,当客户端1暂停之后再回来时,它仍然错误的认为合法持有锁并尝试写文件,导致文件破坏。这里是前面提到的“进程暂停”带来的问题,也体现出分布式锁续租功能的必要性。
Fencing 令牌
前面资源锁的例子中,必须要保证过期的唯一锁不能影响其他正常的部分,则可以使用 fencing 技术,栅栏,隔离之意。
每次授予锁或租约时,同时返回一个 fencing 令牌,该令牌每授予一次就会递增,而每次客户端在请求时都携带 fencing 令牌。
服务器会存储当前已处理的最新令牌,如果有过期令牌过来则会档掉。
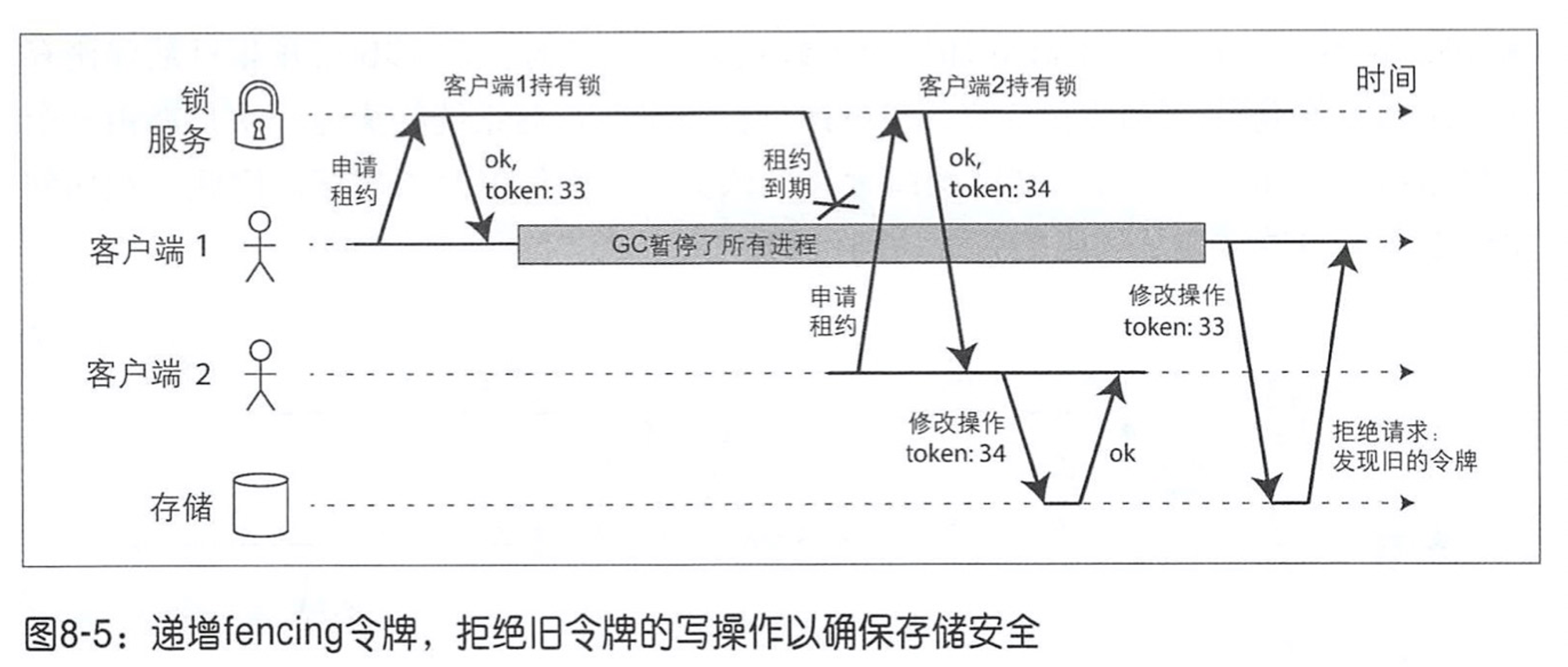
当使用 ZooKeeper 作为锁服务时,可以用事务标识 zxid 或节点版本 cversion 来充当 fencing 令牌。
服务端检查令牌可能看起来有些复杂,但却是推荐做法,系统不能假定所以客户端都表现符合预期,服务端必须防范这种来自客户端的滥用。
拜占庭故障
fencing 令牌可以检测并阻止那些无意的误操作,但对于故意试图破坏,在发送消息时故意伪造令牌即可。可靠不等于诚实。
如果节点存在撒谎的情况那分布式系统处理难度就上了一个台阶。
如果某个系统中即使发生部分节点故障,甚至不遵从协议,或者恶意攻击、干扰网络,但仍可继续正常运行,那么我们称之为拜占庭容错系统。这些担忧在某些特定场景是合理的:
- 航空航天领域,计算机内存或CPU寄存器中的数据可能被辐射破坏,导致以不可预知的方式影响其他节点。这种情况如果将系统下线,代价将异常昂贵。飞机撞毁,杀死船员,火箭与空间站相撞,飞行系统必须做到容忍拜占庭故障。
- 多个参与者的系统中,某些参与者会作弊或欺骗他人,就像比特币和区块链一样的点对点网络,就是互不信任的当事方就某项交易达成一致,且不依赖集中的机制。
弱谎言形式
有些谎言不那么恶意,如硬件问题造成的无效消息,软件bug,配置错误等,可通过如下方式提高系统可靠性和健壮性:
- 校验和等方式识别错误,如TCP UDP
- 检查用户输入,限制输入大小
- 部署多态 NTP服务。
理论系统模型与现实
通过一些系统模型来形式化描述算法的前提条件:
关于计时方面有三种常见的系统模型:
- 同步模型:同步模型假定有上界的网络延迟,有上界的进程暂停和有上界的时钟误差。这并不意味着没有延迟,而是说延迟不会超过固定上界。大多数系统并非同步模型,因为无限延迟和暂停确实可能发生。
- 部分同步模型:大部分情况跟同步系统一样,而少数情况会出现进程暂停和时钟漂移。
- 异步模型:算法不会对时机做任何假设,甚至没有时钟。现实中比较少见。
对于节点失效系统模型:
- 崩溃-中止模型:算法假设一个节点只能以一种方式发生故障,即遭遇系统崩溃。这意味着节点可能再任意时刻突然停止响应,且节点永久消失,无法恢复。
- 崩溃-恢复模型:节点可能在任何时候崩溃,且可能在一段时间后恢复,节点上持久存储的数据会在崩溃后得以保存,而内存中的可能丢失。
- 拜占庭失效模型:节点可能发生任何事,包括试图作弊和欺骗其他节点。
小结
分布式系统中典型问题:
- 网络延迟和数据包丢失。
- 节点时钟不同步,甚至跳跃或倒退。
- 进程可能暂停、失效、再恢复。
如何检测错误,错误出现后如何容忍错误?
貌似本章全是问题,下一章讨论解决方案。